Models in convis.models¶
Convis Models¶
These models are ready to run.
-
class
convis.models.List(*args, **kwargs)[source]¶ A sequential list of Layers that registers its items as submodules and provides tab-completable names with a prefix (by default ‘layer_’).
The list provides a forward function that sequentially applies each module in the list.
Examples
>>> l = convis.models.List() >>> l.append(convis.filters.Conv3d(1, 1, (1,10,10))) >>> l.append(convis.filters.Conv3d(1, 1, (1,10,10))) >>> l.append(convis.filters.Conv3d(1, 1, (1,10,10))) >>> print l.layer_2 Conv3d (1, 1, kernel_size=(1, 10, 10), stride=(1, 1, 1), bias=False) >>> some_input = convis.samples.moving_gratings() >>> o = l.run(some_input,dt=200)
-
class
convis.models.Dict(*args, **kwargs)[source]¶ A dictionary of Layers that registers its items as submodules and provides tab-completable names of unnamed Layers with a prefix (by default ‘layer_’).
The dict provides a forward function that sequentially applies each module in the list in insertion order.
Examples
>>> l = convis.models.List() >>> l.append(convis.filters.Conv3d(1, 1, (1,10,10))) >>> l.append(convis.filters.Conv3d(1, 1, (1,10,10))) >>> l.append(convis.filters.Conv3d(1, 1, (1,10,10))) >>> print l.layer_2 Conv3d (1, 1, kernel_size=(1, 10, 10), stride=(1, 1, 1), bias=False) >>> some_input = convis.samples.moving_gratings() >>> o = l.run(some_input,dt=200)
-
class
convis.models.Sequential(*args)[source]¶ A Model that executes Layers sequentially, passing the output of one as the input of the next.
This class inherits from
torch.nn.Sequentialand offers the same mechanism for enumerating the provided Layers. TheListclass will give modules names starting with ‘layer_’ to make them tab-completable and offers the a similar forward function to compute layers sequentially.Using
Listis recommended overSequential.See also
-
class
convis.models.Parallel(*args, **kwargs)[source]¶ A container to execute layers in parallel. Modules will be added to it in the order they are passed in the constructor. Alternatively, an ordered dict of modules can also be passed in.
Using
Listwith mode=’parallel’ is recommended overParallelif the names of the modules are not relevant.Providing an argument sum will change how the outputs will be combined. This can be a string (‘cat’ for concatenation on axis 0 (batch channel), ‘cat_1’ for concatenating at axis 1 (color channel), ‘cat_2’ for concatenating at time channel, ‘cat_2’ or ‘cat_3’ for concatenating in space, ‘sum’ for total sum,’sum_0’ for summing over axis 0, etc.)
Examples
To make it easier to understand, here is a small example:
# Example of using Parallel conv1 = convis.filters.Conv3d(1,3,(10,1,1),time_pad=True) conv2 = convis.filters.Conv3d(1,3,(10,1,1),time_pad=True) model = nn.Parallel( conv1, conv2, sum = 'cat_1' ) # concatenates the output at dimension 1 model = convis.models.Parallel( convis.filters.Conv3d(1,2,(10,1,1),time_pad=True), convis.filters.Conv3d(1,2,(10,1,1),time_pad=True), sum = convis.filter.Sum(0) ) # concatenates and sums the input at dimension 0 # all other output dimensions MUST be the same! # Example of using Parallel with OrderedDict conv1 = convis.filters.Conv3d(1,3,(10,1,1),time_pad=True) conv2 = convis.filters.Conv3d(1,3,(10,1,1),time_pad=True) model = nn.Parallel(OrderedDict([ ('conv1', conv1), ('relu1', torch.nn.ReLU()), ('conv2', conv2), ('relu2', torch.nn.ReLU()) ]), sum = 'sum_0')
-
convis.models.make_sequential_parallel_model(list_of_layers)[source]¶ Creates an alternating sequential/parallel model starting with a sequential layer.
See also
-
convis.models.make_parallel_sequential_model(list_of_layers)[source]¶ Creates an alternating sequential/parallel model starting with a parallel layer.
See also
-
class
convis.models.LNCascade(n=0, kernel_dim=(1, 1, 1), bias=False, autopad=True, nonlinearity=None)[source]¶ A linear-nonlinear cascade model with a variable number of convolution filters.
Pads input automatically to produce output of the same size as the input.
For each layer, a custom non-linearity can be set. If no non-linearity is set for a specific layer, the default nonlinearity is used.
Parameters: n (int):
number of Conv3d layers added when initialized (by default no layers are added)
kernel_dim (int tuple of time,x,y):
the default dimensions of the convolution filter weights
nonlinearity (Layer, torch.nn.Module or function):
the default nonlinearity to use (defaults to a rectification)
Examples
>>> m = LNCascade(n=2, nonlinearity=lambda x: x.clamp(min=-1.0,max=1.0)) # the default nonlinearity sets a >>> m.nonlinearities[1] = convis.filters.NLRectifySquare() # setting a custom non-linearity for this layer >>> m.linearities[1] = None # no linear filter for this stage >>> m.add_layer(linear=convis.filters.Conv3d(), nonlinear=lambda x: x**2) >>> m.add_layer(linear=convis.filters.SmoothConv(), nonlinear=None) # None uses the default nonlinearity, *not* the identity! >>> m.add_layer(linear=convis.filters.RF(), nonlinear=lambda x: torch.exp(x))
Attributes
linearities (convis.List): list of linear layers nonlinearities (convis.List): list of non-linear layers
-
class
convis.models.L(kernel_dim=(1, 1, 1), bias=False, population=True)[source]¶ A linear model with a convolution filter.
Pads input automatically to produce output of the same size as the input.
Parameters: kernel_dim: tuple(int,int,int) or tuple(int,int,int,int,int)
Either the dimensions of a 3d kernel (time,x,y) or a 5d kernel (out_channels,in_channels,time,x,y).
bias: bool
Whether or not to include a scalar bias parameter in the linear filter
population: bool
If population is True, the last filter will be a convolution filter, creating a population of responses. If population is False, the last filter will be a single receptive field, creating only one output time series.
-
class
convis.models.RF(kernel_dim=(1, 1, 1), bias=False, population=False)[source]¶ A linear model with a receptive field filter.
Pads input automatically to produce output of the same length as the input.
Parameters: kernel_dim: tuple(int,int,int) or tuple(int,int,int,int,int)
Either the dimensions of a 3d kernel (time,x,y) or a 5d kernel (out_channels,in_channels,time,x,y).
bias: bool
Whether or not to include a scalar bias parameter in the linear filter
population: bool
If population is True, the last filter will be a convolution filter, creating a population of responses. If population is False, the last filter will be a single receptive field, creating only one output time series.
-
class
convis.models.LN(kernel_dim=(1, 1, 1), bias=False, population=True)[source]¶ A linear-nonlinear model with a convolution filter.
Pads input automatically to produce output of the same size as the input.
Parameters: kernel_dim: tuple(int,int,int) or tuple(int,int,int,int,int)
Either the dimensions of a 3d kernel (time,x,y) or a 5d kernel (out_channels,in_channels,time,x,y).
bias: bool
Whether or not to include a scalar bias parameter in the linear filter
population: bool
If population is True, the last filter will be a convolution filter, creating a population of responses. If population is False, the last filter will be a single receptive field, creating only one output time series.
-
class
convis.models.LNLN(kernel_dim=(1, 1, 1), bias=False, population=True)[source]¶ A linear-nonlinear cascade model with two convolution filters.
Pads input automatically to produce output of the same size as the input.
Parameters: kernel_dim: tuple(int,int,int) or tuple(int,int,int,int,int)
Either the dimensions of a 3d kernel (time,x,y) or a 5d kernel (out_channels,in_channels,time,x,y).
bias: bool
Whether or not to include a scalar bias parameter in the linear filter
population: bool
If population is True, the last filter will be a convolution filter, creating a population of responses. If population is False, the last filter will be a single receptive field, creating only one output time series.
-
class
convis.models.LNFDLNF(kernel_dim=(1, 1, 1), bias=False, feedback_length=50, population=True)[source]¶ A linear-nonlinear cascade model with two convolution filters, feedback for each layer and individual delays.
Pads input automatically to produce output of the same size as the input.
Parameters: kernel_dim: tuple(int,int,int) or tuple(int,int,int,int,int)
Either the dimensions of a 3d kernel (time,x,y) or a 5d kernel (out_channels,in_channels,time,x,y).
bias: bool
Whether or not to include a scalar bias parameter in the linear filter
feedback_length: int
Feedback is implemented as a temporal convolution filter, feedback_length is the maximal possible delay.
population: bool
If population is True, the last filter will be a convolution filter, creating a population of responses. If population is False, the last filter will be a single receptive field, creating only one output time series.
-
class
convis.models.Retina(opl=True, bipolar=True, gang=True, spikes=True)[source]¶ A retinal ganglion cell model comparable to VirtualRetina [Wohrer200901].
[Wohrer200901] Wohrer, A., & Kornprobst, P. (2009). Virtual Retina: a biological retina model and simulator, with contrast gain control. Journal of Computational Neuroscience, 26(2), 219-49. http://doi.org/10.1007/s10827-008-0108-4 See also
convis.base.Layer- The Layer base class, providing chunking and optimization
convis.filters.retina.OPL- The outer plexiform layer performs luminance to contrast conversion
convis.filters.retina.Bipolar- provides contrast gain control
convis.filters.retina.GanglionInput- provides a static non-linearity and a last spatial integration
convis.filters.retina.GanglionSpiking- creates spikes from an input current
Examples
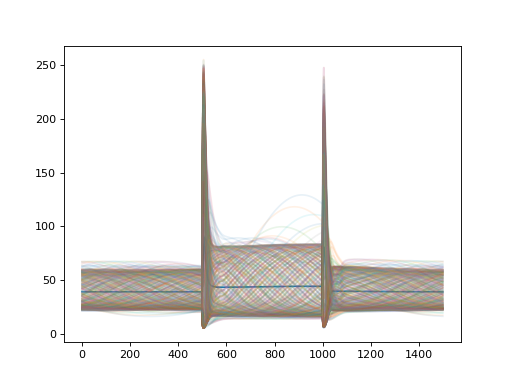
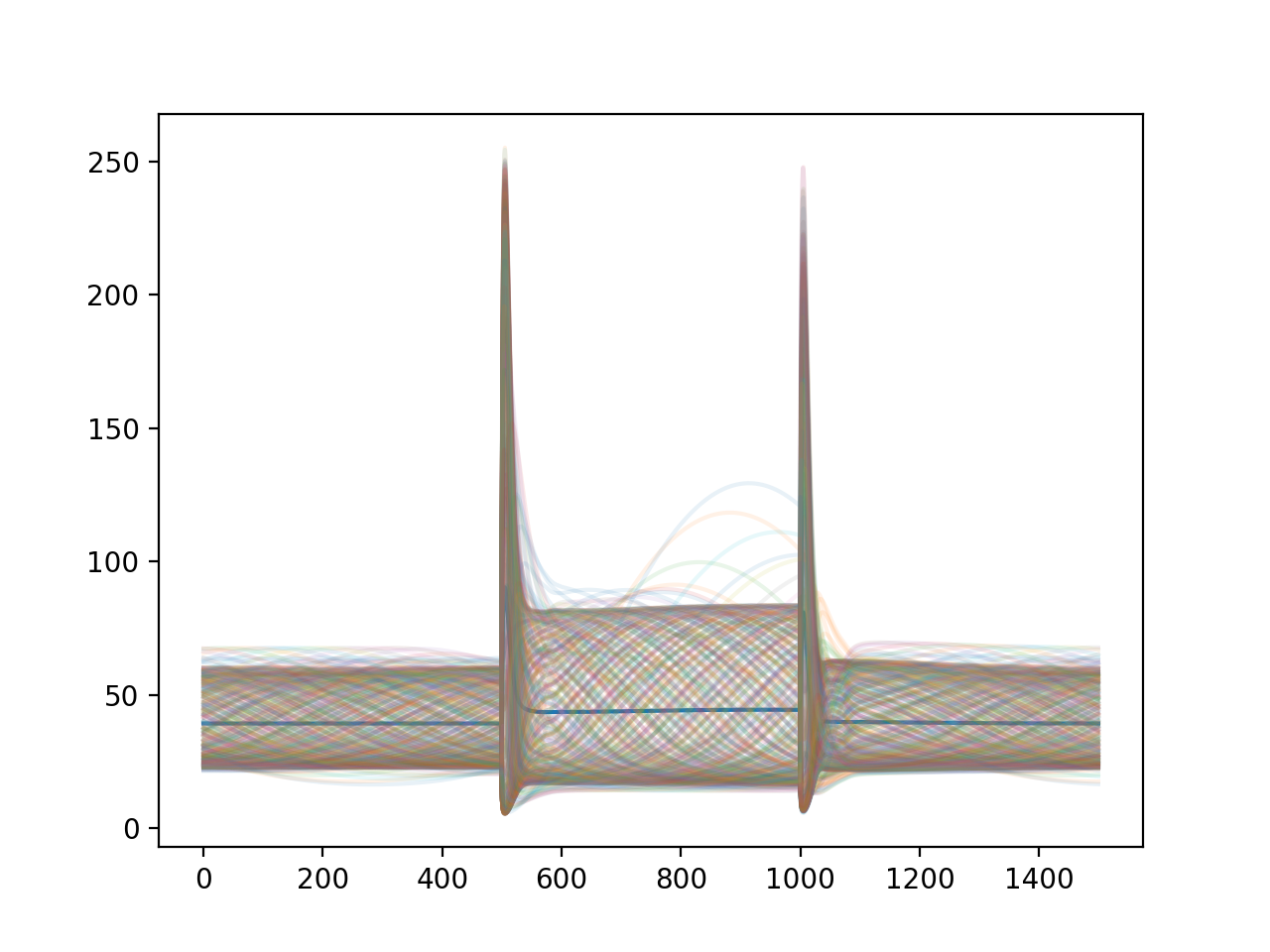
import convis import numpy as np from matplotlib import pylab as plt retina = convis.retina.Retina() inp = convis.samples.moving_grating(2000) inp = np.concatenate([inp[:1000],2.0*inp[1000:1500],inp[1500:2000]],axis=0) o_init = retina.run(inp[:500],dt=200) o = retina.run(inp[500:],dt=200) convis.plot_5d_time(o[0],mean=(3,4)) # plots the mean activity over time plt.figure() retina = convis.retina.Retina(opl=True,bipolar=False,gang=True,spikes=False) o_init = retina.run(inp[:500],dt=200) o = retina.run(inp[500:],dt=200) convis.plot_5d_time(o[0],mean=(3,4)) # plots the mean activity over time convis.plot_5d_time(o[0],alpha=0.1) # plots a line for each pixel
Attributes
opl (Layer (convis.filters.retina.OPL)) bipolar (Layer (convis.filters.retina.Bipolar)) gang_0_input (Layer (convis.filters.retina.GanglionInput)) gang_0_spikes (Layer (convis.filters.retina.GanglionSpiking)) gang_1_input (Layer (convis.filters.retina.GanglionInput)) gang_1_spikes (Layer (convis.filters.retina.GanglionSpiking)) _timing (list of tuples) timing information of the last run (last chunk) Each entry is a tuple of (function that was executed, number of seconds it took to execute) keep_timing_info (bool) whether to store all timing information in a list timing_info (list) stores timing information of all runs if keep_timing_info is True.
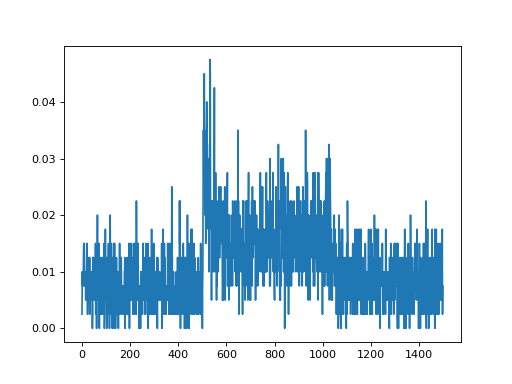
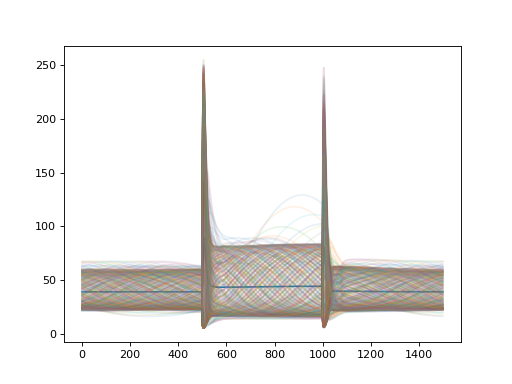
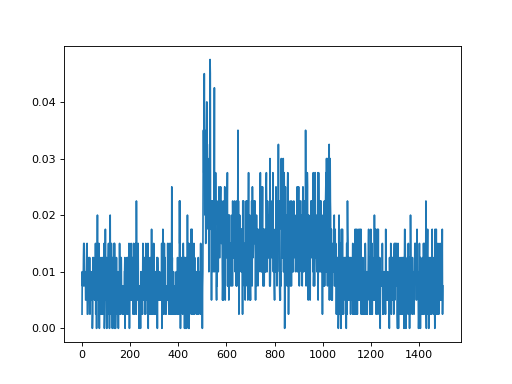{kind=link}
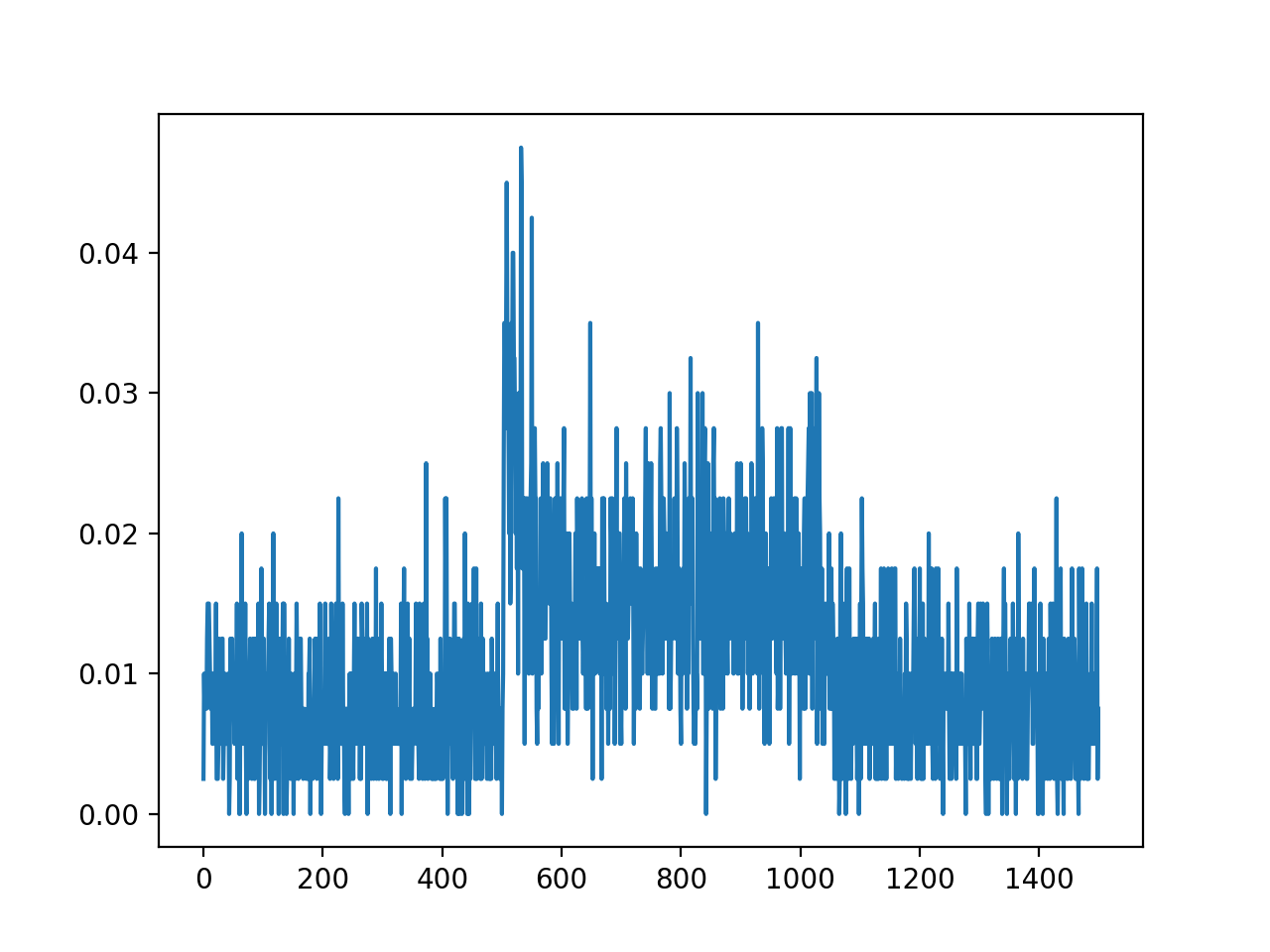{kind=link}
{kind=link}
{kind=link}
-
class
convis.models.McIntosh(filter_size=(10, 5, 5), random_init=True, out_channels=1, filter_2_size=(1, 1, 1), layer1_channels=8, layer2_channels=16)[source]¶ Convolutional Retina Model
Contains two convolutional layers and one readout layer.
The first convolutional layer has 8 channels. The second convolutional layer has 16 channels. The readout is a linear combination over all space and all channels of layer 2, resulting in out_channels many output channels.
To set the weights individually:
m = convis.models.McIntosh(out_channels=5) m.layer1.set_weight(np.random.randn(8,1,20,10,10)) # mapping from 1 to 8 channels m.layer2.set_weight(np.random.randn(16,8,10,50,50)) # mapping from 8 to 16 channels # the readout needs some number of outputs # and 16 x the number of pixels of the image as inputs m.readout.set_weight(np.random.randn(5,16*input.shape[-2]*input.shape[-1])) # plotting the parameters: m.plot()
[1] Mcintosh, L. T., Maheswaranathan, N., Nayebi, A., Ganguli, S., & Baccus, S. A. (2016). Deep Learning Models of the Retinal Response to Natural Scenes. Advances in Neural Information Processing Systems 29 (NIPS), (Nips), 1-9. Also: arXiv:1702.01825 [q-bio.NC]
Models are essentially the same as filters: they are both
classes that inherit most of their capabilities from Layer.
The split into two submodules is an effort to sort them by
complexity / generalizability. Eg. all filters can be combined into
more complex models (combining models does not always make sense)
and all models are ready to “do things”, which is not the case for eg.
the TimePadding filter.
If you feel the distinction is unnecessary, or you came up with a better way to separate Layers into submodules, let me know by submitting a github issue!
Combinators¶
These classes can build simple models out of a sequence of Layers by either combining them sequentially (the output of one layer is the input of the next), or in parallel (all layers get the same input).
-
class
convis.models.Sequential(*args)[source] A Model that executes Layers sequentially, passing the output of one as the input of the next.
This class inherits from
torch.nn.Sequentialand offers the same mechanism for enumerating the provided Layers. TheListclass will give modules names starting with ‘layer_’ to make them tab-completable and offers the a similar forward function to compute layers sequentially.Using
Listis recommended overSequential.See also
-
class
convis.models.List(*args, **kwargs)[source] A sequential list of Layers that registers its items as submodules and provides tab-completable names with a prefix (by default ‘layer_’).
The list provides a forward function that sequentially applies each module in the list.
Examples
>>> l = convis.models.List() >>> l.append(convis.filters.Conv3d(1, 1, (1,10,10))) >>> l.append(convis.filters.Conv3d(1, 1, (1,10,10))) >>> l.append(convis.filters.Conv3d(1, 1, (1,10,10))) >>> print l.layer_2 Conv3d (1, 1, kernel_size=(1, 10, 10), stride=(1, 1, 1), bias=False) >>> some_input = convis.samples.moving_gratings() >>> o = l.run(some_input,dt=200)
-
append(module)[source] Appends a module to the end of the list.
Returns: the list itself
-
extend(modules)[source] Extends the list with modules from a Python iterable.
Returns: the list itself
-
-
class
convis.models.Parallel(*args, **kwargs)[source] A container to execute layers in parallel. Modules will be added to it in the order they are passed in the constructor. Alternatively, an ordered dict of modules can also be passed in.
Using
Listwith mode=’parallel’ is recommended overParallelif the names of the modules are not relevant.Providing an argument sum will change how the outputs will be combined. This can be a string (‘cat’ for concatenation on axis 0 (batch channel), ‘cat_1’ for concatenating at axis 1 (color channel), ‘cat_2’ for concatenating at time channel, ‘cat_2’ or ‘cat_3’ for concatenating in space, ‘sum’ for total sum,’sum_0’ for summing over axis 0, etc.)
Examples
To make it easier to understand, here is a small example:
# Example of using Parallel conv1 = convis.filters.Conv3d(1,3,(10,1,1),time_pad=True) conv2 = convis.filters.Conv3d(1,3,(10,1,1),time_pad=True) model = nn.Parallel( conv1, conv2, sum = 'cat_1' ) # concatenates the output at dimension 1 model = convis.models.Parallel( convis.filters.Conv3d(1,2,(10,1,1),time_pad=True), convis.filters.Conv3d(1,2,(10,1,1),time_pad=True), sum = convis.filter.Sum(0) ) # concatenates and sums the input at dimension 0 # all other output dimensions MUST be the same! # Example of using Parallel with OrderedDict conv1 = convis.filters.Conv3d(1,3,(10,1,1),time_pad=True) conv2 = convis.filters.Conv3d(1,3,(10,1,1),time_pad=True) model = nn.Parallel(OrderedDict([ ('conv1', conv1), ('relu1', torch.nn.ReLU()), ('conv2', conv2), ('relu2', torch.nn.ReLU()) ]), sum = 'sum_0')
Linear-Nonlinear Models¶
-
class
convis.models.L(kernel_dim=(1, 1, 1), bias=False, population=True)[source] A linear model with a convolution filter.
Pads input automatically to produce output of the same size as the input.
Parameters: kernel_dim: tuple(int,int,int) or tuple(int,int,int,int,int)
Either the dimensions of a 3d kernel (time,x,y) or a 5d kernel (out_channels,in_channels,time,x,y).
bias: bool
Whether or not to include a scalar bias parameter in the linear filter
population: bool
If population is True, the last filter will be a convolution filter, creating a population of responses. If population is False, the last filter will be a single receptive field, creating only one output time series.
-
class
convis.models.LN(kernel_dim=(1, 1, 1), bias=False, population=True)[source] A linear-nonlinear model with a convolution filter.
Pads input automatically to produce output of the same size as the input.
Parameters: kernel_dim: tuple(int,int,int) or tuple(int,int,int,int,int)
Either the dimensions of a 3d kernel (time,x,y) or a 5d kernel (out_channels,in_channels,time,x,y).
bias: bool
Whether or not to include a scalar bias parameter in the linear filter
population: bool
If population is True, the last filter will be a convolution filter, creating a population of responses. If population is False, the last filter will be a single receptive field, creating only one output time series.
-
class
convis.models.LNCascade(n=0, kernel_dim=(1, 1, 1), bias=False, autopad=True, nonlinearity=None)[source] A linear-nonlinear cascade model with a variable number of convolution filters.
Pads input automatically to produce output of the same size as the input.
For each layer, a custom non-linearity can be set. If no non-linearity is set for a specific layer, the default nonlinearity is used.
Parameters: n (int):
number of Conv3d layers added when initialized (by default no layers are added)
kernel_dim (int tuple of time,x,y):
the default dimensions of the convolution filter weights
nonlinearity (Layer, torch.nn.Module or function):
the default nonlinearity to use (defaults to a rectification)
Examples
>>> m = LNCascade(n=2, nonlinearity=lambda x: x.clamp(min=-1.0,max=1.0)) # the default nonlinearity sets a >>> m.nonlinearities[1] = convis.filters.NLRectifySquare() # setting a custom non-linearity for this layer >>> m.linearities[1] = None # no linear filter for this stage >>> m.add_layer(linear=convis.filters.Conv3d(), nonlinear=lambda x: x**2) >>> m.add_layer(linear=convis.filters.SmoothConv(), nonlinear=None) # None uses the default nonlinearity, *not* the identity! >>> m.add_layer(linear=convis.filters.RF(), nonlinear=lambda x: torch.exp(x))
Attributes
linearities (convis.List): list of linear layers nonlinearities (convis.List): list of non-linear layers
-
class
convis.models.LNLN(kernel_dim=(1, 1, 1), bias=False, population=True)[source] A linear-nonlinear cascade model with two convolution filters.
Pads input automatically to produce output of the same size as the input.
Parameters: kernel_dim: tuple(int,int,int) or tuple(int,int,int,int,int)
Either the dimensions of a 3d kernel (time,x,y) or a 5d kernel (out_channels,in_channels,time,x,y).
bias: bool
Whether or not to include a scalar bias parameter in the linear filter
population: bool
If population is True, the last filter will be a convolution filter, creating a population of responses. If population is False, the last filter will be a single receptive field, creating only one output time series.
-
class
convis.models.LNFDLNF(kernel_dim=(1, 1, 1), bias=False, feedback_length=50, population=True)[source] A linear-nonlinear cascade model with two convolution filters, feedback for each layer and individual delays.
Pads input automatically to produce output of the same size as the input.
Parameters: kernel_dim: tuple(int,int,int) or tuple(int,int,int,int,int)
Either the dimensions of a 3d kernel (time,x,y) or a 5d kernel (out_channels,in_channels,time,x,y).
bias: bool
Whether or not to include a scalar bias parameter in the linear filter
feedback_length: int
Feedback is implemented as a temporal convolution filter, feedback_length is the maximal possible delay.
population: bool
If population is True, the last filter will be a convolution filter, creating a population of responses. If population is False, the last filter will be a single receptive field, creating only one output time series.
Convolution Model¶
-
class
convis.models.McIntosh(filter_size=(10, 5, 5), random_init=True, out_channels=1, filter_2_size=(1, 1, 1), layer1_channels=8, layer2_channels=16)[source] Convolutional Retina Model
Contains two convolutional layers and one readout layer.
The first convolutional layer has 8 channels. The second convolutional layer has 16 channels. The readout is a linear combination over all space and all channels of layer 2, resulting in out_channels many output channels.
To set the weights individually:
m = convis.models.McIntosh(out_channels=5) m.layer1.set_weight(np.random.randn(8,1,20,10,10)) # mapping from 1 to 8 channels m.layer2.set_weight(np.random.randn(16,8,10,50,50)) # mapping from 8 to 16 channels # the readout needs some number of outputs # and 16 x the number of pixels of the image as inputs m.readout.set_weight(np.random.randn(5,16*input.shape[-2]*input.shape[-1])) # plotting the parameters: m.plot()
[1] Mcintosh, L. T., Maheswaranathan, N., Nayebi, A., Ganguli, S., & Baccus, S. A. (2016). Deep Learning Models of the Retinal Response to Natural Scenes. Advances in Neural Information Processing Systems 29 (NIPS), (Nips), 1-9. Also: arXiv:1702.01825 [q-bio.NC]
Finding all Layers in one submodules convis.layers¶
convis.layers now contains all Layers
from convis.filters and convis.models. If you are
unsure whether something is only a “filter” or a already a “model”,
they can all be found in the same module now. Still, convis.filters
and convis.models will continue to be available separately.
import convis
len(dir(convis.layers))