Streams convis.streams¶
The streams module contains Stream classes that can load different kinds of data.
Streams that are usable currently are: RandomStream, SequenceStream and ImageSequence.
All others are experimental. If you plan on using any of them, you can open a enhancement issue on the issue tracker.
Since some streams do not have a defined end, the argument max_t can specify for how long a model should be executed.
import convis
model = convis.models.Retina()
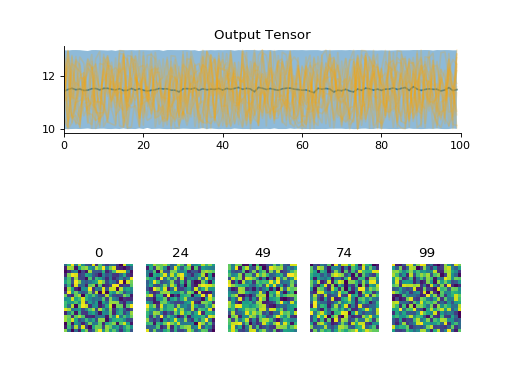
inp = convis.streams.RandomStream((20,20),mean=127,level=100.0)
o = model.run(inp,dt=100, max_t=1000)
convis.plot(o[0])
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
-
class
convis.streams.InrImageStreamer(filename, z=False, slice_at=None)[source]¶ Reads a large inr file and is an iterator over all images.
By default, the z dimension is ignored. Setting z to True changes this, such that each image is 3d instead of 2d.Warning
This class is not currently maintained and might change without notice between releases.
-
get(i=1)[source]¶ outputs the next slice of length i in the stream (see
convis.streams.Stream())
-
-
class
convis.streams.InrImageStreamWriter(filename, v=1, x=1, y=1, z=1, time_dimension='VDIM')[source]¶ Warning
This class is not currently maintained and might change without notice between releases.
-
class
convis.streams.InrImageFileStreamer(filenames)[source]¶ Warning
This class is not currently maintained and might change without notice between releases.
-
class
convis.streams.Stream(size=(50, 50), pixel_per_degree=10, t_zero=0.0, t=0.0, dt=0.001)[source]¶ Stream Base Class
Streams have to have methods to either get(i) or put a frame.
- get(i) takes i frames from the stream and changes the internal state.
- put(t) inserts a torch.Tensor or numpy.ndarray into the stream (eg. saving it into a file).
-
get(i)[source]¶ outputs the next slice of length i in the stream (see
convis.streams.Stream())
-
class
convis.streams.ProcessingStream(input_stream, model, pre=None, post=None)[source]¶ Combines a stream and a Layer (model or filter) into a new stream.
Each slice will be processed at once (using Layer.__call__, not Layer.run), so a limited number of frames should be requested at any one time.
New in version 0.6.4.
Parameters: input_stream : convis.streams.Stream
The stream that is used as input to the model
model : convis.Layer
The model that transforms slices of the input_stream into outputs
pre : function or None
Optional operation to be done one each slice before handing it to the model.
post : function or None
Optional operation to be done one each slice after the model has processed it.
Examples
To recreate the neuromorphic MNIST stream one can combine the MNIST stream and a Poisson layer. The output of the MNIST stream can be scaled with a function passed to pre.
import convis stream = convis.streams.MNISTStream('../data',rep=10) model = convis.filters.spiking.Poisson() stream2 = convis.streams.ProcessingStream(stream,model,pre=lambda x: 0.1*x)
-
class
convis.streams.RandomStream(size=(50, 50), pixel_per_degree=10, level=1.0, mean=0.0)[source]¶ creates a stream of random frames.
Examples
(Source code, png, hires.png, pdf)
-
get(i)[source]¶ outputs the next slice of length i in the stream (see
convis.streams.Stream())
-
{kind=link}
{kind=link}
-
class
convis.streams.SequenceStream(sequence=array([], shape=(0, 50, 50), dtype=float64), size=None, pixel_per_degree=10, max_frames=5000)[source]¶ 3d Numpy array that represents a sequence of images
Warning
This class is not currently maintained and might change without notice between releases.
Examples
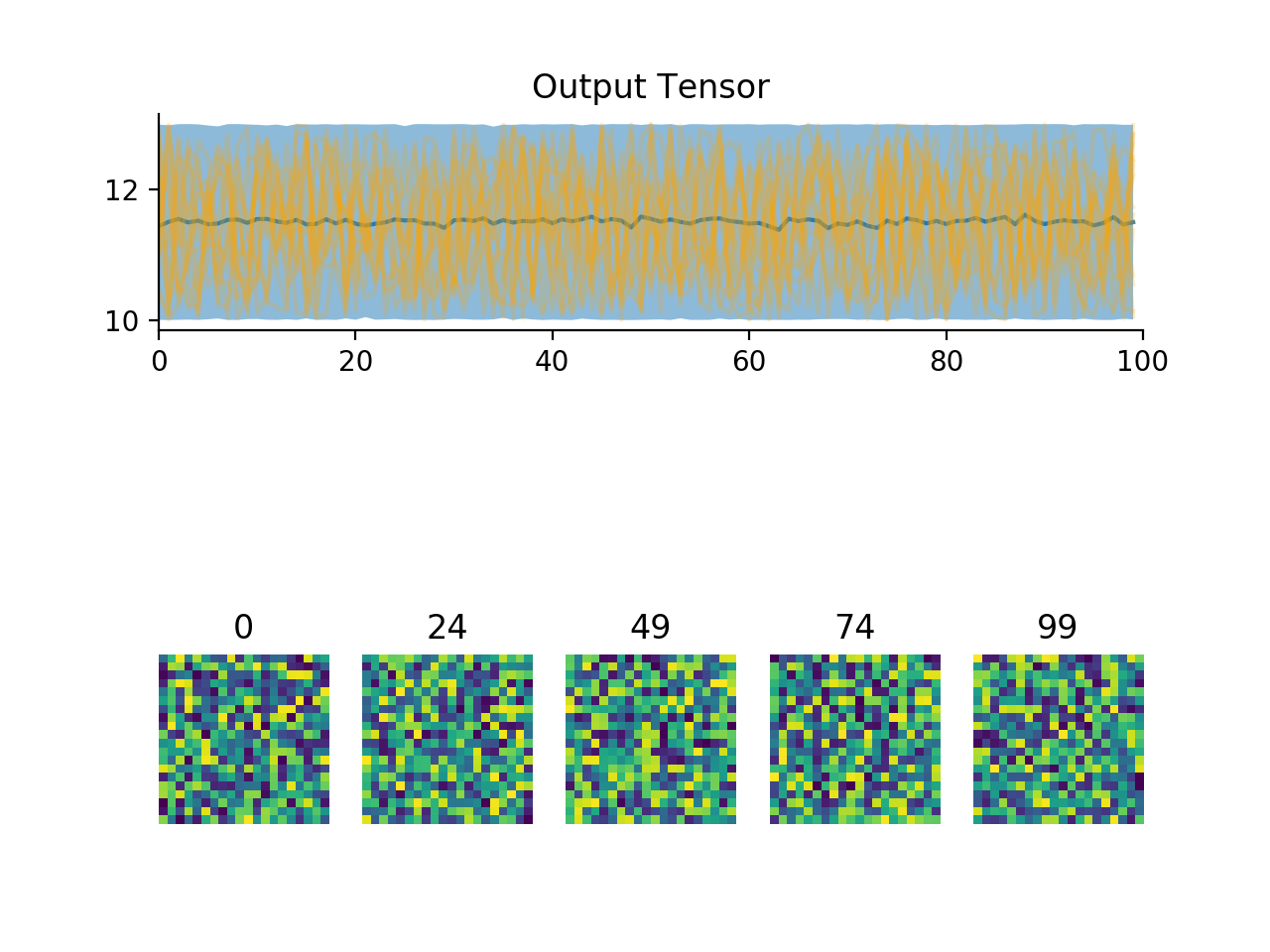
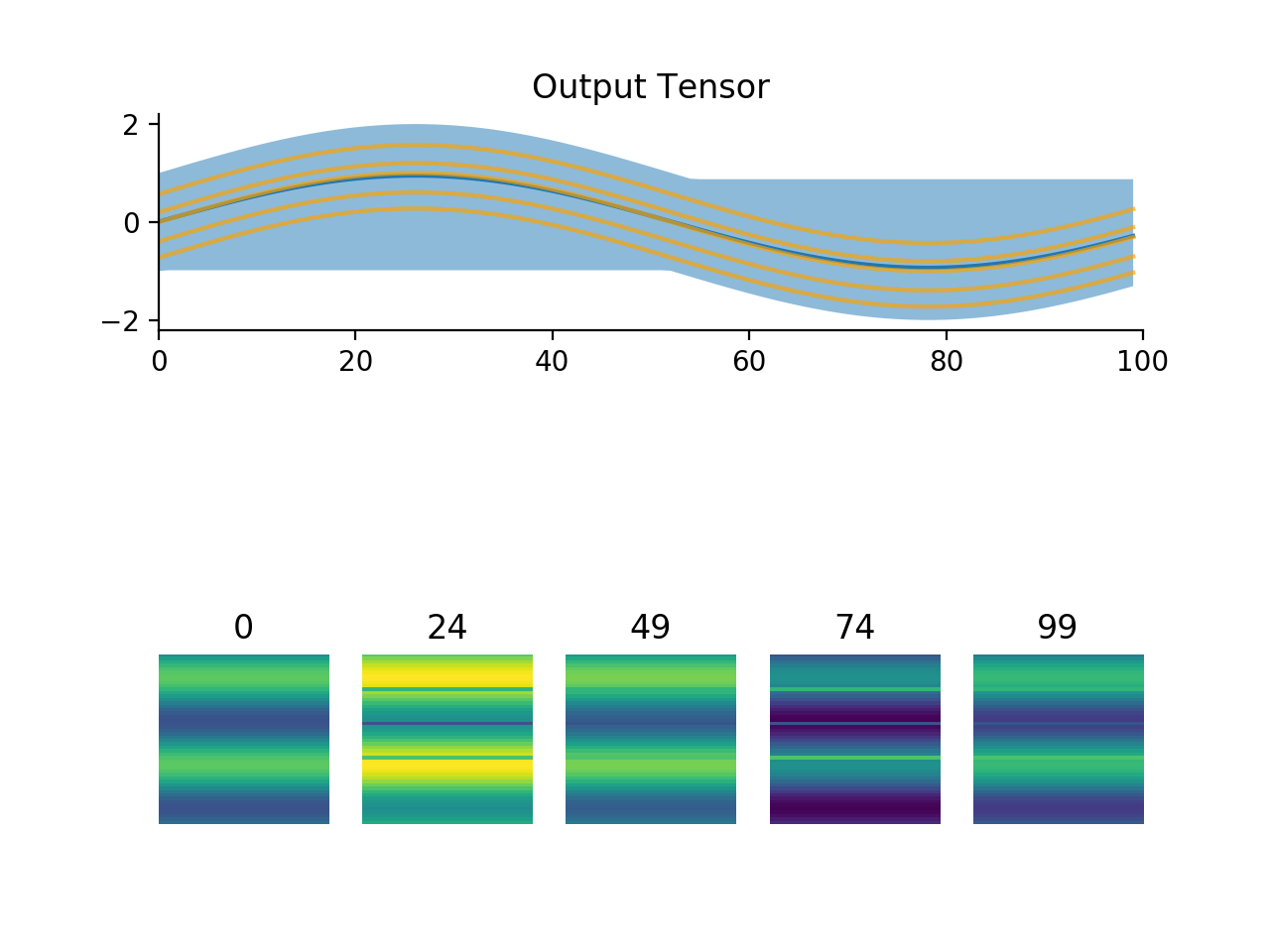
import convis x = np.ones((200,50,50)) x[:,10,:] = 0.0 x[:,20,:] = 0.0 x[:,30,:] = 0.0 x *= np.sin(np.linspace(0.0,12.0,x.shape[0]))[:,None,None] x += np.sin(np.linspace(0.0,12.0,x.shape[1]))[None,:,None] inp = convis.streams.SequenceStream(x) convis.plot(inp.get(100))
(Source code, png, hires.png, pdf)
-
get(i)[source]¶ outputs the next slice of length i in the stream (see
convis.streams.Stream())
-
{kind=link}
{kind=link}
-
class
convis.streams.RepeatingStream(sequence=array([], shape=(0, 50, 50), dtype=float64), size=None, pixel_per_degree=10)[source]¶ Warning
This class is not currently maintained and might change without notice between releases.
-
get(i)[source]¶ outputs the next slice of length i in the stream (see
convis.streams.Stream())
-
-
class
convis.streams.TimedSequenceStream(sequence=array([], shape=(0, 50, 50), dtype=float64), size=None, pixel_per_degree=10, t_zero=0.0, dt=0.001)[source]¶ 3d Numpy array that represents a sequence of images
Warning
This class is not currently maintained and might change without notice between releases.
-
class
convis.streams.TimedResampleStream(stream, t_zero=0.0, dt=0.001)[source]¶ 3d Numpy array that represents a sequence of images
Warning
This class is not currently maintained and might change without notice between releases.
-
class
convis.streams.NumpyReader(file_ref, size=None, pixel_per_degree=10)[source]¶ reads a numpy file.
Warning
This class is not currently maintained and might change without notice between releases.
-
get(i=1)[source]¶ outputs the next slice of length i in the stream (see
convis.streams.Stream())
-
-
class
convis.streams.VideoReader(filename=0, size=(50, 50), offset=None, dt=0.041666666666666664, mode='mean')[source]¶ filename can be either a device number or the path to a video file. The file will be opened as such: cv2.VideoCapture(filename)
If only one camera is connected, it can be selected with 0. If more than one camera is connected,
Warning
This class is not currently maintained and might change without notice between releases.
Parameters: filename (int or str):
a string containing the url/path to a file or a number signifying a camera
size (tuple of int, int):
The size of the frames cut from the video
offset (None or tuple of int, int):
The offset of the part cut from the video
dt (float):
(does nothing right now)
mode (str):
color mode: ‘mean’, ‘r’, ‘g’, ‘b’ or ‘rgb’ Default is taking the mean over all color channels ‘rgb’ will give a 5d output (does not work with all Output Streams)
New in version 0.6.4.
Examples
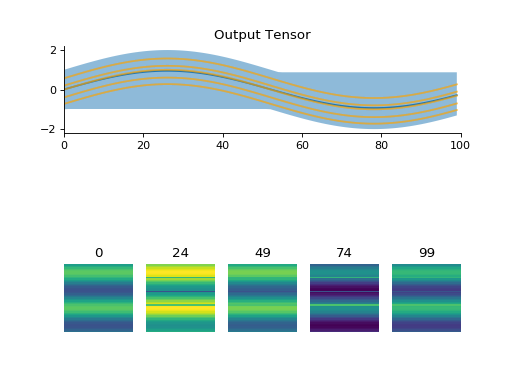
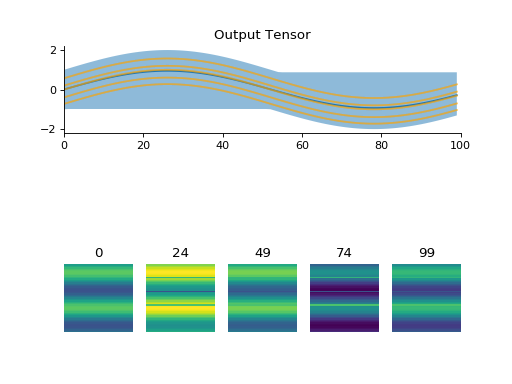
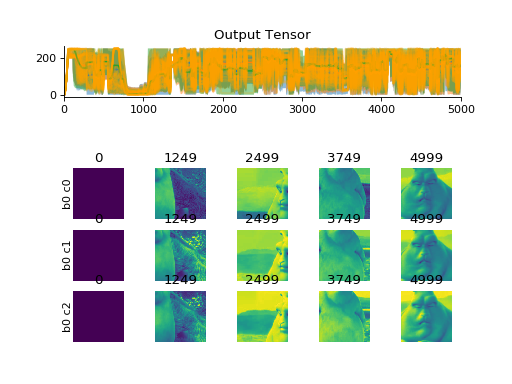
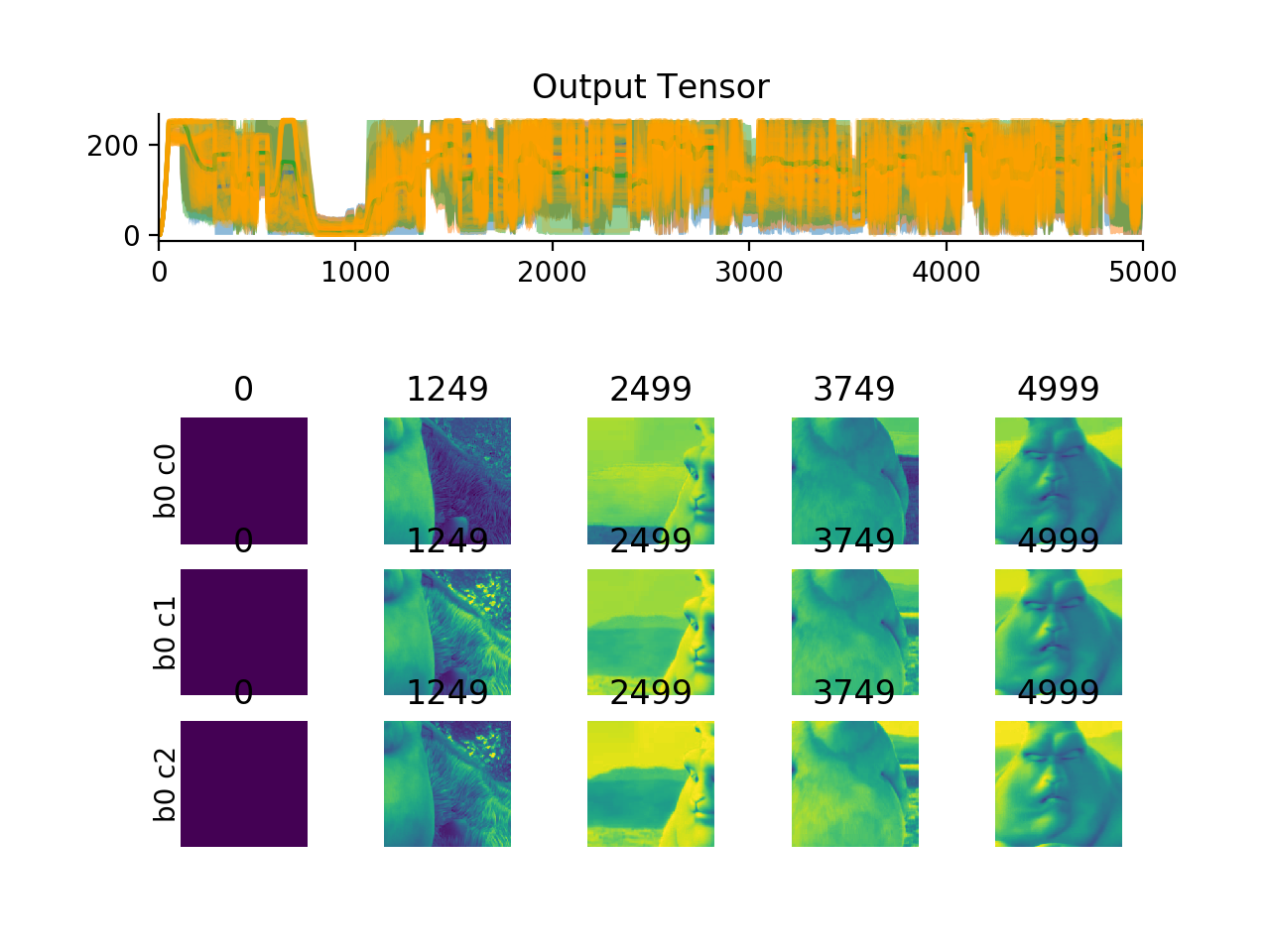
import convis vid_in = convis.streams.VideoReader('/home/jacob/convis/input.avi',size=(200,200),mode='rgb') convis.plot_tensor(vid_in.get(5000)) # shows three channels
(Source code, png, hires.png, pdf)
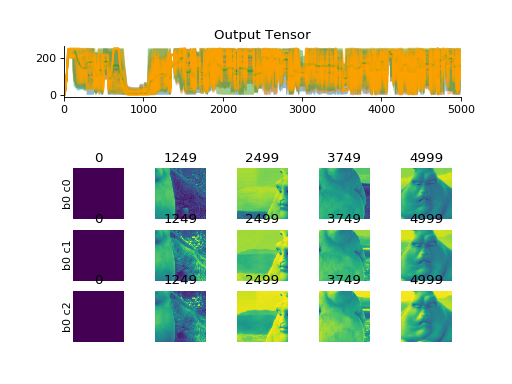
import convis vid_in = convis.streams.VideoReader('some_video.mp4',size=(200,200),mode='mean') retina = convis.models.Retina() o = retina.run(vid_in, dt=200, max_t=2000) # run for 2000 frames
-
get(i)[source]¶ outputs the next slice of length i in the stream (see
convis.streams.Stream())
-
{kind=link}
{kind=link}
-
class
convis.streams.VideoWriter(filename='output.avi', size=(50, 50), codec='XVID', isColor=True)[source]¶ Writes data to a video
Warning
This class is not currently maintained and might change without notice between releases.
Parameters: filename (str):
Video file where output should be written to (extension determines format)
size ((int,int) tuple):
the size of the output
codec (str):
possible codecs: ‘DIVX’, ‘XVID’, ‘MJPG’, ‘X264’, ‘WMV1’, ‘WMV2’ (see also: `http://www.fourcc.org/codecs.php`_ ) default: ‘XVID’
isColor (bool):
whether the video is written in color or grey scale If color input is written to the file when isColor is False, the mean over all channels will be taken If the input is bw and isColor is True, the color channels will be duplicated (resulting in a bw image).
New in version 0.6.4.
Examples
VideoReaderandVideoWriterwork together in color and black/white:import convis vid_in = convis.streams.VideoReader(some_video.mp4',size=(200,200),mode='rgb') vid_out = convis.streams.VideoWriter('test.mp4',size=(200,200),codec='X264') vid_out.put(vid_in.get(1000)) # copy 1000 color frames vid_out.close() vid_in.close()
import convis vid_in = convis.streams.VideoReader('some_video.mp4',size=(200,200),mode='mean') vid_out = convis.streams.VideoWriter('test.mp4',size=(200,200),isColor=False) vid_out.put(vid_in.get(1000)) # copy 1000 black-and-white frames vid_out.close() vid_in.close()
-
class
convis.streams.ImageSequence(filenames='*.jpg', size=(50, 50), repeat=1, offset=None, is_color=False)[source]¶ loads a sequence of images so they can be processed by convis
The image values will be scaled between 0 and 256.
When is_color is True, it returns a 5d array with dimensions [0,color_channel,time,x,y].
If offset is None, the crop will be chosen as the center of the image.
Warning
This function is not stable and might change without notice between releases. To create stable code it is currently recommended to load input manually into numpy arrays.
Parameters: filenames : str or list
List of filenames or a wildcard expression (eg. ‘frame_*.jpeg’) of the images to load.
size : two tuple (int,int)
the size the output image should be cropped to
repeat : int
how often each image should be repeated (eg. 100 to show a new image after 100 frames)
offset : None or (int,int)
offset of the crop from the top left corner of the image
is_color : bool
Whether images should be interpreted as color or grayscale. If is_color is True, this stream gives a 5d output.
Examples
Choosing a crop with size and offset:
import convis inp = convis.streams.ImageSequence('cat.png', repeat=100, size=(10,10), offset=(10,50))
Creating a 500 frame input:
inp = convis.streams.ImageSequence(['cat.png']*500) convis.plot(inp.get(100))
inp = convis.streams.ImageSequence('cat.png', repeat=500) convis.plot(inp.get(100))
Loading multiple images:
inp = convis.streams.ImageSequence('frame_*.png', repeat=10) convis.plot(inp.get(100))
inp = convis.streams.ImageSequence(['cat.png','dog.png','parrot.png'], repeat=200) convis.plot(inp.get(100))
Attributes
self.i (int) : internal frame counter Methods
get(i) retrieve a sequence of i frames. Advances the internal counter. -
get(i)[source]¶ outputs the next slice of length i in the stream (see
convis.streams.Stream())
-
-
class
convis.streams.MNISTStream(data_folder='./mnist_data', rep=10, max_value=1.0, init=None, advance=179425529, include_label=False)[source]¶ Downloads MNIST data and displays random digits.
The digits are chosen pseudo randomly using a starting value init and a (large) advancing value. If both values are supplied, the stream will return the same sequence of numbers. By default, init is chosen randomly and advance is set to an arbitrary (but fixed) high prime number. If advance shares factors with the number of samples in MNIST, not all examples will be covered!
If include_label is True, the output will contain a second channel with the matching label. (Currently, there is no automated way to pass this along with the other channel)
Note
The way the label is encoded might change depending on how people want to use it. Please submitting a github issue if you have in idea how to pass labels along with the input!
The output of the stream will be frames of 28 x 28 pixels.
New in version 0.6.4.
Parameters: data_folder : str
A (relative or absolute) path where the MNIST data should be downloaded to. If a valid download is found at that location, the existing data will be used. This stream uses torchvision to download and extract the data, more info about the downloader can be found here.
rep : int
Number of frames each digit should be repeated
max_value : float
The stimuli will have normalized values between 0 and max_value.
init : int or None
The starting point of the pseudo-random walk through the examples. If the value is None, it is chosen randomly with uniform probability.
advance : int
A large number that determines the next sample. If this value is not touched, it will generate pseudo-random walks starting deterministically from init.
include_label : bool
Whether to include an additional channel carrying the labels or not (default: False)
buffer : torch.Tensor
the MNIST dataset
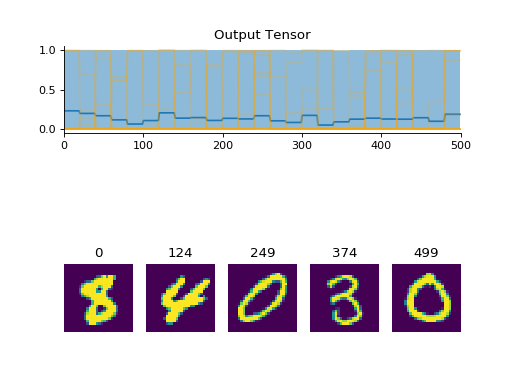
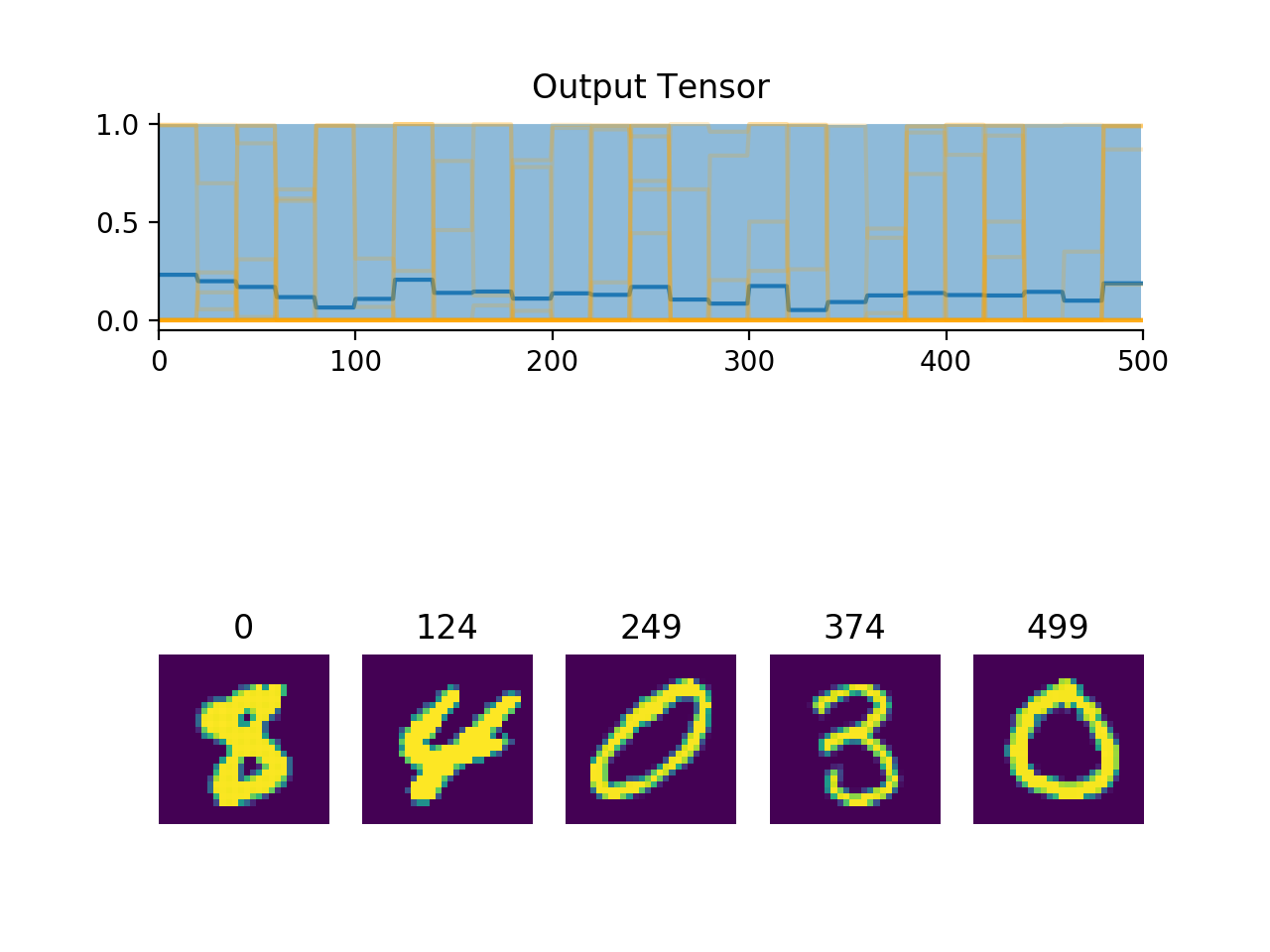
Examples
import convis from matplotlib.pylab import plot, xlim, gcf stream = convis.streams.MNISTStream('../data',rep=20) convis.plot(stream.get(500)) gcf().show() convis.plot(stream.get(500)) gcf().show() stream.reset() # returning to the start convis.plot(stream.get(500)) gcf().show()
(Source code, png, hires.png, pdf)
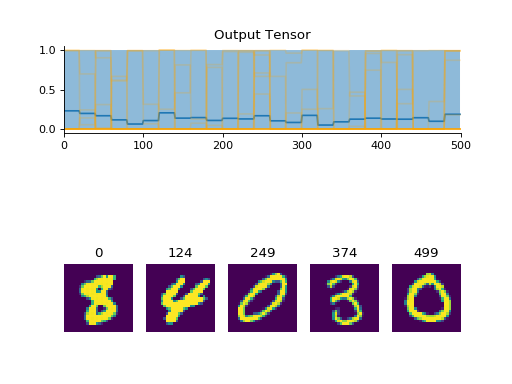
Attributes
i (int) index of current image. j (int) number of repetitions already displayed (secondary index) init_i (int) The initial starting point of the walk. -
get(i=1)[source]¶ outputs the next slice of length i in the stream (see
convis.streams.Stream())
-
{kind=link}
{kind=link}
-
class
convis.streams.PoissonMNISTStream(data_folder='./mnist_data', rep=10, fr=0.05, init=None, advance=179425529, include_label=False)[source]¶ Downloads MNIST data and generates Poisson spiking for random digits.
This definition of a neuromorphic version of the MNIST data set follows eg.:
- Diehl and M. Cook. Unsupervised learning of digit recognition using spike-timing-dependent plasticity. Frontiers in Computational Neuroscience, 9(99), 2015.
- Querlioz, O. Bichler, P. Dollfus, and C. Gamrat. Immunity to device variations in a spiking neural network with memristive nanodevices. IEEE Transactions on Nanotechnology, 12:288-295, 2013.
An alternative interpretation are events that are created by saccade-like movements over the images.
The digits are chosen pseudo randomly using a starting value init and a (large) advancing value. If both values are supplied, the stream will return the same sequence of numbers. By default, init is chosen randomly and advance is set to an arbitrary (but fixed) high prime number. If advance shares factors with the number of samples in MNIST, not all examples will be covered!
If include_label is True, the output will contain a second channel with the matching label. (Currently, there is no automated way to pass this along with the other channel)
The output of the stream will be frames of 28 x 28 pixels of binary coded spike trains.
New in version 0.6.4.
Parameters: data_folder : str
A (relative or absolute) path where the MNIST data should be downloaded to. If a valid download is found at that location, the existing data will be used. This stream uses torchvision to download and extract the data, more info about the downloader can be found here.
rep : int
Number of frames each digit should be repeated
fr : float
The firing probability at the highest possible value.
init : int or None
The starting point of the pseudo-random walk through the examples. If the value is None, it is chosen randomly with uniform probability.
advance : int
A large number that determines the next sample. If this value is not touched, it will generate pseudo-random walks starting deterministically from init.
include_label : bool
Whether to include an additional channel carrying the labels or not (default: False)
buffer : torch.Tensor
the MNIST dataset
Examples
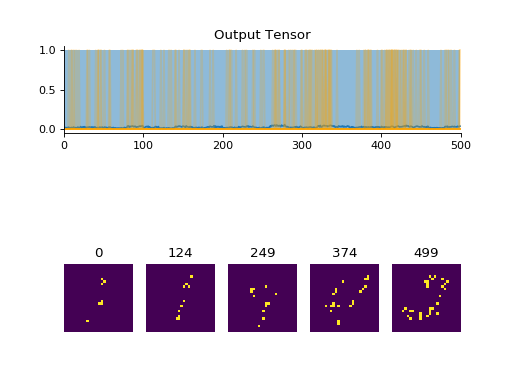
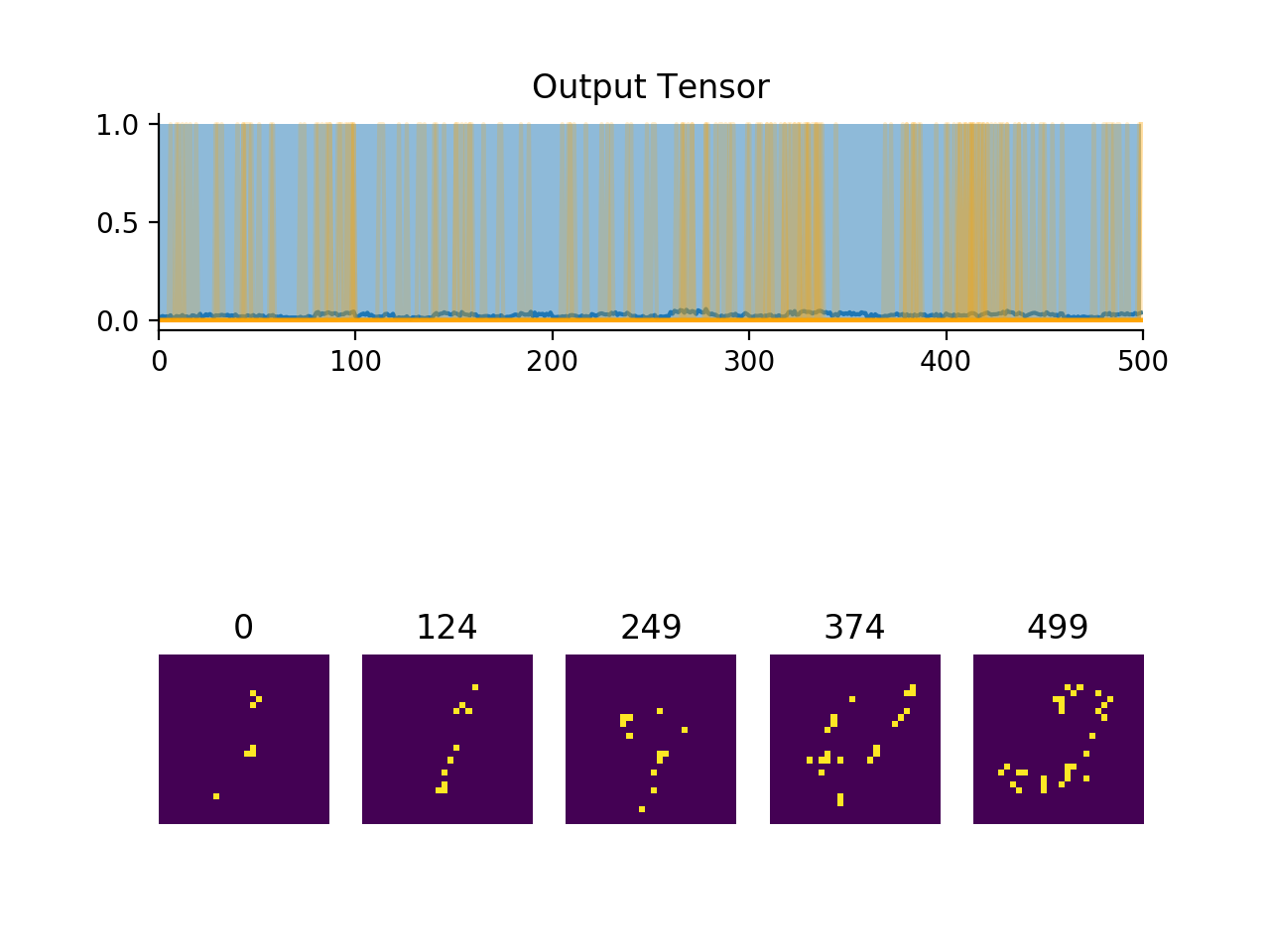
import convis from matplotlib.pylab import plot, xlim, gcf stream = convis.streams.PoissonMNISTStream('../data',rep=20,fr=0.20) # here we are using a very high firing rate for easy visualization # (20% of cells are active in each frame) convis.plot(stream.get(500)) gcf().show() convis.plot(stream.get(500)) gcf().show() stream.reset() # returning to the start convis.plot(stream.get(500)) gcf().show()
(Source code, png, hires.png, pdf)
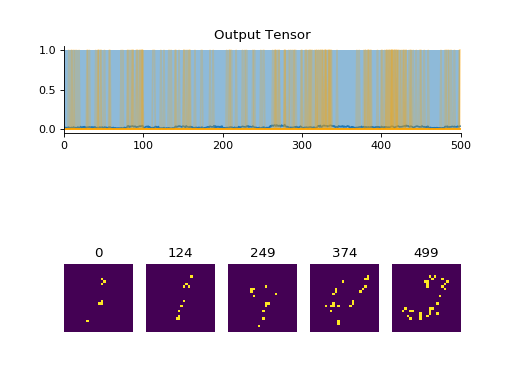
Attributes
i (int) index of current image. j (int) number of repetitions already displayed (secondary index) init_i (int) The initial starting point of the walk. -
get(i=1)[source]¶ outputs the next slice of length i in the stream (see
convis.streams.Stream())
{kind=link}
{kind=link}
-
class
convis.streams.PseudoNMNIST(mnist_data_folder='../data/', threshold=5.0, output_size=(34, 34))[source]¶ A motion driven conversion of MNIST into spikes. A quick way to get spiking input.
Internally, it defines a Layer that performs three predetermined “saccades” (see the source code if you want to use it as a Saccade generator in other contexts). It uses a
IntegrativeMotionSensorto generate spikes from the movement.New in version 0.6.4.
Parameters: mnist_data_folder : str
Where to find (or download to) the MNIST dataset. (see
convis.streams.MNISTStream)threshold : float
the sensitivity of the motion detection (smaller values are more sensitive)
output_size : tuple(int,int)
size of the generated output (the data is padded with zeros)
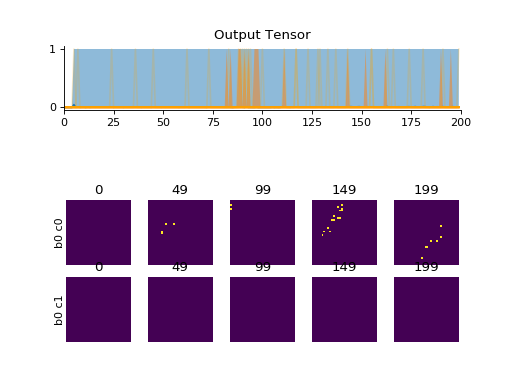
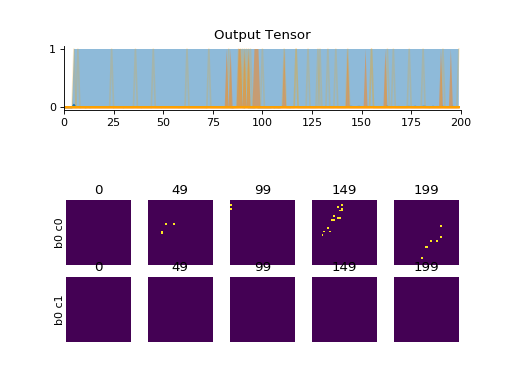
Examples
import convis n = convis.streams.PseudoNMNIST() convis.plot(n.get(200))
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}